这里是Docker实战系列第四篇。主要介绍分布式系统中的元老级组件Zookeeper。
ZooKeeper 是一个开源的分布式协调服务,是Hadoop,HBase和其他分布式框架使用的有组织服务的标准。
分布式应用程序可以基于 ZooKeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。
读过 Docker实战之Consul集群 的小伙伴应该有印象,里边有一张一致性算法的对比图。所有的分布式系统都面临着CAP理论的抉择,都需要一致性算法的保障。这里先放上一个简单的总结,用于大家借鉴那些顶级开源软件在分布式上的思路。
分布式组件
算法/协议
服务
Redis Cluster
Gossip
master提供读写,slave只备份
Zookeeper
ZAB
Leader提供读写,Follower只读,遇到写请求转发给Leader
Kafka
ZK临时节点
只有leader提供读写服务
大致来说,zookeeper 的使用场景如下:
分布式协调
分布式锁
元数据/配置信息管理
HA高可用性
发布/订阅
负载均衡
Master选举
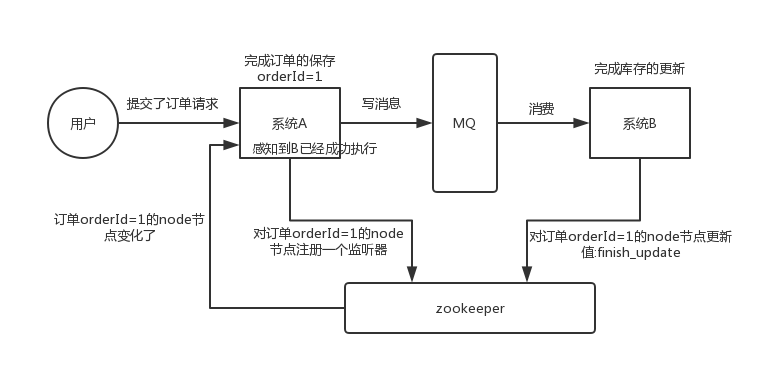
这里引用中华石杉老师的例子
这个其实是 zookeeper 很经典的一个用法,简单来说,就好比,你 A 系统发送个请求到 mq,然后 B 系统消息消费之后处理了。那 A 系统如何知道 B 系统的处理结果?用 zookeeper 就可以实现分布式系统之间的协调工作。A 系统发送请求之后可以在 zookeeper 上对某个节点的值注册个监听器,一旦 B 系统处理完了就修改 zookeeper 那个节点的值,A 系统立马就可以收到通知,完美解决。
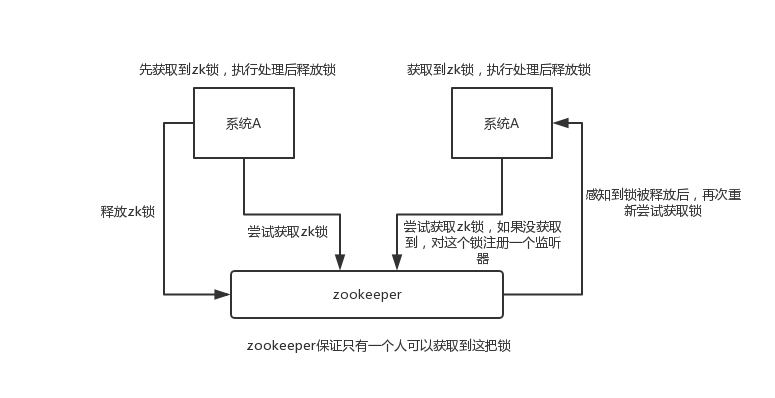
举个栗子。对某一个数据连续发出两个修改操作,两台机器同时收到了请求,但是只能一台机器先执行完另外一个机器再执行。那么此时就可以使用 zookeeper 分布式锁,一个机器接收到了请求之后先获取 zookeeper 上的一把分布式锁,就是可以去创建一个 znode,接着执行操作;然后另外一个机器也尝试去创建那个 znode,结果发现自己创建不了,因为被别人创建了,那只能等着,等第一个机器执行完了自己再执行。
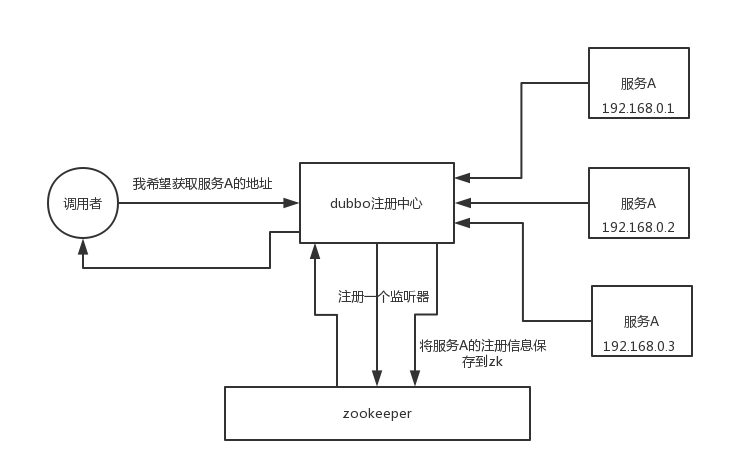
zookeeper 可以用作很多系统的配置信息的管理,比如 kafka、storm 等等很多分布式系统都会选用 zookeeper 来做一些元数据、配置信息的管理,包括 dubbo 注册中心不也支持 zookeeper 么?
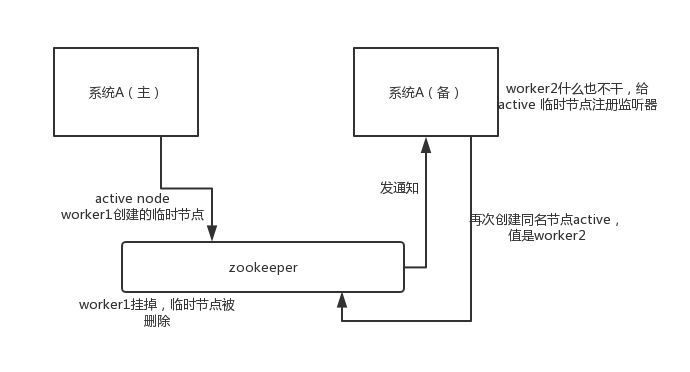
这个应该是很常见的,比如 hadoop、hdfs、yarn 等很多大数据系统,都选择基于 zookeeper 来开发 HA 高可用机制,就是一个重要进程一般会做主备两个,主进程挂了立马通过 zookeeper 感知到切换到备用进程。
docker-compose-zookeeper-cluster.yml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 version: '3.7' networks: docker_net: external: true services: zoo1: image: zookeeper restart: unless-stopped hostname: zoo1 container_name: zoo1 ports: - 2182 :2181 environment: ZOO_MY_ID: 1 ZOO_SERVERS: server.1=0.0.0.0:2888:3888;2181 server.2=zoo2:2888:3888;2181 server.3=zoo3:2888:3888;2181 volumes: - ./zookeeper/zoo1/data:/data - ./zookeeper/zoo1/datalog:/datalog networks: - docker_net zoo2: image: zookeeper restart: unless-stopped hostname: zoo2 container_name: zoo2 ports: - 2183 :2181 environment: ZOO_MY_ID: 2 ZOO_SERVERS: server.1=zoo1:2888:3888;2181 server.2=0.0.0.0:2888:3888;2181 server.3=zoo3:2888:3888;2181 volumes: - ./zookeeper/zoo2/data:/data - ./zookeeper/zoo2/datalog:/datalog networks: - docker_net zoo3: image: zookeeper restart: unless-stopped hostname: zoo3 container_name: zoo3 ports: - 2184 :2181 environment: ZOO_MY_ID: 3 ZOO_SERVERS: server.1=zoo1:2888:3888;2181 server.2=zoo2:2888:3888;2181 server.3=0.0.0.0:2888:3888;2181 volumes: - ./zookeeper/zoo3/data:/data - ./zookeeper/zoo3/datalog:/datalog networks: - docker_net
启动集群
1 docker-compose -f docker-compose-zookeeper-cluster.yml up -d
在ZAB算法中,存在Leader、Follower、Observer三种角色,现在我们就来认识下它们。
1 2 3 4 5 6 ➜ docker docker exec -it zoo1 /bin/sh ZooKeeper JMX enabled by default Using config: /conf/zoo.cfg Client port found: 2181. Client address: localhost. Mode: follower
由上结果可知,zoo1是follower
1 2 3 4 5 6 ➜ docker docker exec -it zoo2 /bin/sh ZooKeeper JMX enabled by default Using config: /conf/zoo.cfg Client port found: 2181. Client address: localhost. Mode: follower
由上结果可知,zoo2是follower
1 2 3 4 5 6 ➜ docker docker exec -it zoo3 /bin/sh ZooKeeper JMX enabled by default Using config: /conf/zoo.cfg Client port found: 2181. Client address: localhost. Mode: leader
由上结果可知,zoo3是leader。负责集群的读写。
1 2 3 4 5 6 7 8 9 10 11 ➜ docker echo srvr | nc localhost 2184 Zookeeper version: 3.5.6-c11b7e26bc554b8523dc929761dd28808913f091, built on 10/08/2019 20:18 GMT Latency min/avg/max: 0/0/0 Received: 2 Sent: 1 Connections: 1 Outstanding: 0 Zxid: 0x100000000 Mode: leader Node count: 5 Proposal sizes last/min/max: -1/-1/-1
如果实践了上述操作的小伙伴一定会发现,映射路径下的文件夹多了好多东西,感兴趣的小伙伴可以打开看一下,了解下ZAB的选举算法(没错,里边记录的就是选举相关的数据)。
1 2 3 4 5 6 7 8 9 10 11 ➜ zookeeper cd zoo1 ➜ zoo1 tree . ├── data │ ├── myid │ └── version-2 │ ├── acceptedEpoch │ ├── currentEpoch │ └── snapshot.0 └── datalog └── version-2
注意:留意currentEpoch中的数值
5.1 模拟Leader掉线
1 2 ➜ zoo1 docker stop zoo3 zoo3
查看此时的选举结果(操作同查看角色操作步骤)。可以看到Zookeeper集群重新选举结果: zoo2被选为leader
5.2 zoo3节点重新上线
1 2 ➜ zoo1 docker start zoo3 zoo3
查看zoo3角色,发现zoo3自动作为follower加入集群。
注意:查看currentEpoch中的数值,存储值为2,代表经过了2次选举。第一次为刚启动时触发选举,第二次为leader宕机后重新选举
笔者本地有安装的Zookeeper环境,所以这里用本地的zkCli进行测试。
1 2 3 4 5 6 7 8 9 10 zkCli -server localhost:2182,localhost:2183,localhost:2184 Connecting to localhost:2182,localhost:2183,localhost:2184 Welcome to ZooKeeper! JLine support is enabled WATCHER:: WatchedEvent state:SyncConnected type :None path:null [zk: localhost:2182,localhost:2183,localhost:2184(CONNECTED) 0] ls / [zookeeper]
顺序节点保证znode路径将是唯一的。
1 2 3 4 [zk: localhost:2182,localhost:2183,localhost:2184(CONNECTED) 1] create -s /zk-test 123 Created /zk-test0000000000 [zk: localhost:2182,localhost:2183,localhost:2184(CONNECTED) 2] ls / [zk-test0000000000, zookeeper]
当会话过期或客户端断开连接时,临时节点将被自动删除
1 2 3 4 [zk: localhost:2182,localhost:2183,localhost:2184(CONNECTED) 3] create -e /zk-temp 123 Created /zk-temp [zk: localhost:2182,localhost:2183,localhost:2184(CONNECTED) 4] ls / [zk-test0000000000, zookeeper, zk-temp]
临时节点在客户端会话结束后就会自动删除,下面使用quit命令行退出客户端,再次连接后即可验证。
1 2 3 4 5 6 7 8 9 10 11 12 [zk: localhost:2182,localhost:2183,localhost:2184(CONNECTED) 5] quit Quitting... ➜ docker zkCli -server localhost:2182,localhost:2183,localhost:2184 Connecting to localhost:2182,localhost:2183,localhost:2184 Welcome to ZooKeeper! JLine support is enabled WATCHER:: WatchedEvent state:SyncConnected type :None path:null [zk: localhost:2182,localhost:2183,localhost:2184(CONNECTED) 0] ls / [zk-test0000000000, zookeeper]
1 2 3 4 [zk: localhost:2182,localhost:2183,localhost:2184(CONNECTED) 1] create /zk-permanent 123 Created /zk-permanent [zk: localhost:2182,localhost:2183,localhost:2184(CONNECTED) 2] ls / [zk-permanent, zk-test0000000000, zookeeper]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 [zk: localhost:2182,localhost:2183,localhost:2184(CONNECTED) 3] get / cZxid = 0x0 ctime = Thu Jan 01 08:00:00 CST 1970 mZxid = 0x0 mtime = Thu Jan 01 08:00:00 CST 1970 pZxid = 0x400000008 cversion = 3 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 0 numChildren = 3 [zk: localhost:2182,localhost:2183,localhost:2184(CONNECTED) 4] ls2 / [zk-permanent, zk-test0000000000, zookeeper] cZxid = 0x0 ctime = Thu Jan 01 08:00:00 CST 1970 mZxid = 0x0 mtime = Thu Jan 01 08:00:00 CST 1970 pZxid = 0x400000008 cversion = 3 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 0 numChildren = 3
使用 ls2 命令来查看某个目录包含的所有文件,与ls不同的是它查看到time、version等信息
1 2 3 4 5 6 7 8 9 10 11 12 [zk: localhost:2182,localhost:2183,localhost:2184(CONNECTED) 5] set /zk-permanent 456 cZxid = 0x400000008 ctime = Tue Mar 03 21:35:20 CST 2020 mZxid = 0x400000009 mtime = Tue Mar 03 21:40:11 CST 2020 pZxid = 0x400000008 cversion = 0 dataVersion = 1 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 3 numChildren = 0
1 2 3 4 5 6 7 8 9 10 11 12 [zk: localhost:2182,localhost:2183,localhost:2184(CONNECTED) 6] stat /zk-permanent cZxid = 0x400000008 ctime = Tue Mar 03 21:35:20 CST 2020 mZxid = 0x400000009 mtime = Tue Mar 03 21:40:11 CST 2020 pZxid = 0x400000008 cversion = 0 dataVersion = 1 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 3 numChildren = 0
1 2 3 [zk: localhost:2182,localhost:2183,localhost:2184(CONNECTED) 7] rmr /zk-permanent [zk: localhost:2182,localhost:2183,localhost:2184(CONNECTED) 8] ls / [zk-test0000000000, zookeeper]
公众号【当我遇上你】, 每天带给你不一样的内容