Apache Kafka是一个快速、可扩展的、高吞吐、可容错的分布式发布订阅消息系统。其具有高吞吐量、内置分区、支持数据副本和容错的特性,适合在大规模消息处理场景中使用。
笔者之前在物联网公司工作,其中Kafka作为物联网MQ选型的事实标准,这里优先给大家搭建Kafka集群环境。由于Kafka的安装需要依赖Zookeeper,对Zookeeper还不了解的小伙伴可以在 这里 先认识下Zookeeper。
Kafka能解决什么问题呢?先说一下消息队列常见的使用场景吧,其实场景有很多,但是比较核心的有 3 个:解耦、异步、削峰。
Kafka部分名词解释如下:
Broker:消息中间件处理结点,一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群。
Topic:一类消息,例如page view日志、click日志等都可以以topic的形式存在,Kafka集群能够同时负责多个topic的分发。
Partition:topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。
Segment:partition物理上由多个segment组成,下面有详细说明。
offset:每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中。partition中的每个消息都有一个连续的序列号叫做offset,用于partition唯一标识一条消息.每个partition中的消息都由offset=0开始记录消息。
配合上一节的Zookeeper环境,计划搭建一个3节点的集群。宿主机IP为 192.168.124.5。
docker-compose-kafka-cluster.yml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 version: '3.7' networks: docker_net: external: true services: kafka1: image: wurstmeister/kafka restart: unless-stopped container_name: kafka1 ports: - "9093:9092" external_links: - zoo1 - zoo2 - zoo3 environment: KAFKA_BROKER_ID: 1 KAFKA_ADVERTISED_HOST_NAME: 192.168 .124 .5 KAFKA_ADVERTISED_PORT: 9093 KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.124.5:9093 KAFKA_ZOOKEEPER_CONNECT: "zoo1:2181,zoo2:2181,zoo3:2181" volumes: - "./kafka/kafka1/docker.sock:/var/run/docker.sock" - "./kafka/kafka1/data/:/kafka" networks: - docker_net kafka2: image: wurstmeister/kafka restart: unless-stopped container_name: kafka2 ports: - "9094:9092" external_links: - zoo1 - zoo2 - zoo3 environment: KAFKA_BROKER_ID: 2 KAFKA_ADVERTISED_HOST_NAME: 192.168 .124 .5 KAFKA_ADVERTISED_PORT: 9094 KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.124.5:9094 KAFKA_ZOOKEEPER_CONNECT: "zoo1:2181,zoo2:2181,zoo3:2181" volumes: - "./kafka/kafka2/docker.sock:/var/run/docker.sock" - "./kafka/kafka2/data/:/kafka" networks: - docker_net kafka3: image: wurstmeister/kafka restart: unless-stopped container_name: kafka3 ports: - "9095:9092" external_links: - zoo1 - zoo2 - zoo3 environment: KAFKA_BROKER_ID: 3 KAFKA_ADVERTISED_HOST_NAME: 192.168 .124 .5 KAFKA_ADVERTISED_PORT: 9095 KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.124.5:9095 KAFKA_ZOOKEEPER_CONNECT: "zoo1:2181,zoo2:2181,zoo3:2181" volumes: - "./kafka/kafka3/docker.sock:/var/run/docker.sock" - "./kafka/kafka3/data/:/kafka" networks: - docker_net kafka-manager: image: sheepkiller/kafka-manager:latest restart: unless-stopped container_name: kafka-manager hostname: kafka-manager ports: - "9000:9000" links: - kafka1 - kafka2 - kafka3 external_links: - zoo1 - zoo2 - zoo3 environment: ZK_HOSTS: zoo1:2181,zoo2:2181,zoo3:2181 TZ: CST-8 networks: - docker_net
执行以下命令启动
1 docker-compose -f docker-compose-kafka-cluster.yml up -d
可以看到kafka集群已经启动成功。
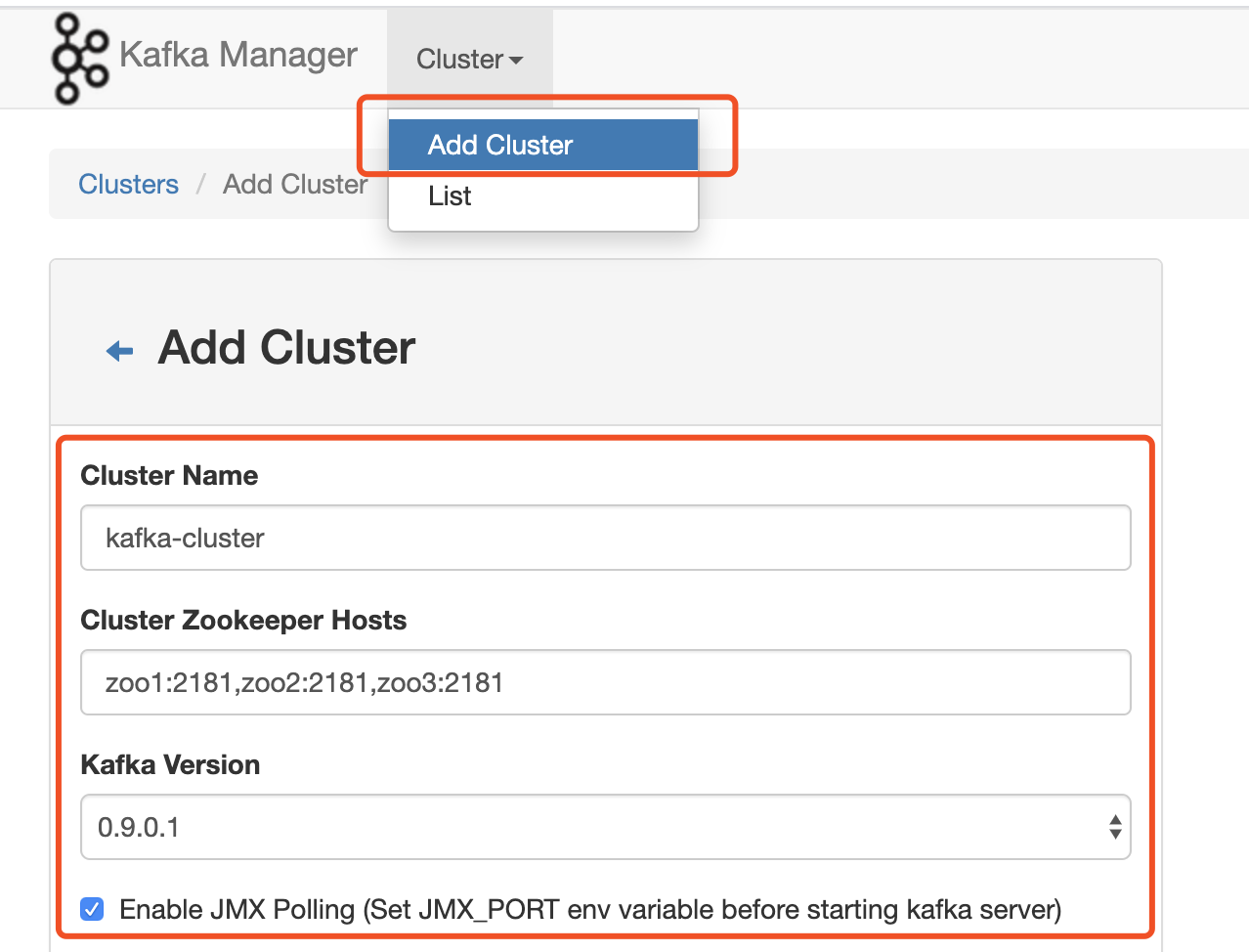
细心的小伙伴发现上边的配置除了kafka外还有一个kafka-manager模块。它是kafka的可视化管理模块。因为kafka的元数据、配置信息由Zookeeper管理,这里我们在UI页面做下相关配置。
1. 访问 http:localhost:9000 ,按图示添加相关配置
2. 配置后我们可以看到默认有一个topic(__consumer_offsets),3个brokers。该topic分50个partition,用于记录kafka的消费偏移量。
1. 首先观察下根目录
kafka基于zookeeper,kafka启动会将元数据保存在zookeeper中。查看zookeeper节点目录,会发现多了很多和kafka相关的目录。结果如下:
1 2 3 4 5 6 7 8 9 10 ➜ docker zkCli -server 127.0 .0.1 :2183 Connecting to 127.0 .0.1 :2183 Welcome to ZooKeeper! JLine support is enabled WATCHER:: WatchedEvent state:SyncConnected type:None path:null [zk: 127.0 .0.1 :2183 (CONNECTED) 0 ] ls / [cluster, controller, brokers, zookeeper, admin, isr_change_notification, log_dir_event_notification, controller_epoch, zk-test0000000000, kafka-manager, consumers, latest_producer_id_block, config]
2. 查看我们映射的kafka目录,新版本的kafka偏移量不再存储在zk中,而是在kafka自己的环境中。
我们节选了部分目录(包含2个partition)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 ├── kafka1 │ ├── data │ │ └── kafka-logs-c4e2e9edc235 │ │ ├── __consumer_offsets-1 │ │ │ ├── 00000000000000000000.index // segment索引文件 │ │ │ ├── 00000000000000000000.log // 数据文件 │ │ │ ├── 00000000000000000000.timeindex // 消息时间戳索引文件 │ │ │ └── leader-epoch-checkpoint ... │ │ ├── __consumer_offsets-7 │ │ │ ├── 00000000000000000000.index │ │ │ ├── 00000000000000000000.log │ │ │ ├── 00000000000000000000.timeindex │ │ │ └── leader-epoch-checkpoint │ │ ├── cleaner-offset-checkpoint │ │ ├── log-start-offset-checkpoint │ │ ├── meta.properties │ │ ├── recovery-point-offset-checkpoint │ │ └── replication-offset-checkpoint │ └── docker.sock
结果与Kafka-Manage显示结果一致。图示的文件是一个Segment,00000000000000000000.log表示offset从0开始,随着数据不断的增加,会有多个Segment文件。
1 2 3 4 5 6 ➜ docker docker exec -it kafka1 /bin/bash bash-4.4 bash-4.4 __consumer_offsets bash-4.4 Created topic test .
说明:
新建主题后, 再次查看映射目录, 由图可见,partition在3个broker上均匀分布。图示同步副本表示当前和主节点数据保持同步的副本数。kafka服务端可以设置 min.insync.replicas 参数(最小同步副本)。这个值必须大于 1,这个是要求一个 leader 至少感知到有至少一个 follower 还跟自己保持联系,没掉队,这样才能确保 leader 挂了还有一个 follower (一种保证消息可靠不丢失的策略)。
ISR是由leader维护,follower从leader同步数据有一些延迟 (包括延迟时间replica.lag.time.max.ms和延迟条数replica.lag.max.messages两个维度, 当前最新的版本0.10.x中只支持replica.lag.time.max.ms这个维度), 任意一个超过阈值都会把follower剔除出ISR, 存入OSR(Outof-Sync Replicas)列表,新加入的follower也会先存放在OSR中。AR=ISR+OSR。
docker中的data路径示例: /kafka/kafka-logs-c4e2e9edc235/test-0/00000000000000000000.log
brew安装的kafka指令路径 /usr/local/Cellar/kafka/2.6.0_1/bin
真正的脚本路径 /usr/local/Cellar/kafka/2.6.0_1/libexec/bin
配置文件路径 /usr/local/etc/kafka
数据存储在 /usr/local/var/lib/kafka-logs 目录下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 ├── connect-distributed ├── connect-mirror-maker ├── connect-standalone ├── kafka-acls ├── kafka-broker-api-versions ├── kafka-configs ├── kafka-console-consumer ├── kafka-console-producer ├── kafka-consumer-groups ├── kafka-consumer-perf-test ├── kafka-delegation-tokens ├── kafka-delete-records ├── kafka-dump-log ├── kafka-leader-election ├── kafka-log-dirs ├── kafka-mirror-maker ├── kafka-preferred-replica-election ├── kafka-producer-perf-test ├── kafka-reassign-partitions ├── kafka-replica-verification ├── kafka-run-class ├── kafka-server-start ├── kafka-server-stop ├── kafka-streams-application-reset ├── kafka-topics ├── kafka-verifiable-consumer ├── kafka-verifiable-producer ├── trogdor ├── zookeeper-security-migration ├── zookeeper-server-start ├── zookeeper-server-stop └── zookeeper-shell
kafka-topics.sh: 用来创建,删除,查看,改变一个topic参数的工具kafka-reassign-partitions.sh: 用来对partition进行重新分配(管理员会较多使用)kafka-log-dirs.sh: 用来查看指定broker下日志目录的使用空间kafka-leader-election.sh: 用于一组Topic分区的leader重新分配,可以支持优先副本和非同步副本(不在ISR中),老版本中的kafka-preferred-replica-election.sh脚本kafka-replica-verification.sh: 该工具可以用来检查topic的一组副本的数据是否一致kafka-broker-api-versions.sh: 用来查看指定broker当前支持的各个接口的版本(kafka高版本已经保证了向下兼容)kafka-configs.sh: 用来操作和查看topic, client, user or broker的实体配置
kafka-console-consumer.sh: 通过终端来启动消费者kafka-console-producer.sh: 通过终端来启动生产者kafka-consumer-groups.sh: 用来查看,删除或者重置消费者组offsetkafka-consumer-perf-test.sh: 用来进行消费者压力测试kafka-producer-perf-test.sh: 用来进行生产者压力测试kafka-delete-records.sh: 删除指定分区的记录,直到指定的offsetkafka-mirror-maker.sh: 用于多集群之间同步topic数据kafka-server-start.sh: broker启动脚本kafka-server-stop.sh: broker关闭脚本kafka-streams-application-reset.sh: 流式应用工具zookeeper-shell.sh: kafka工具中也默认提供了zookeeper管理工具(不太好用)
topic创建
--create: 创建topic
--replication-factor: 指定副本数量(仅在创建时可用)
--config: 指定topic级别的参数(动态参数,可修改)
--replica-assignment: 手动指定partition到broker的分配<part1_replica1:part1_replica2,part2_replica1:part2_replica2>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 # 创建topic ➜ bin ./kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --create --topic test Created topic test. # 查看默认创建topic的参数详情(由broker配置决定) # 默认1个分区,1个副本 ➜ bin ./kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --describe --topic test Topic: test PartitionCount: 1 ReplicationFactor: 1 Configs: segment.bytes=1073741824 Topic: test Partition: 0 Leader: 1 Replicas: 1 Isr: 1 # 指定参数创建topic, 2个分片, 1个副本 # 指定分区partitions为2,副本replication-factor为1,topic数据保留2分钟 # replication<=broker(一定); # 有效消费者数<=partitions分区数(一定); ➜ bin ./kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --create --topic test1 --partitions 2 --replication-factor 1 --config retention.ms=120000 Created topic test1. # 分区,副本和指定参数都改变了,2个分片, 1个副本 ➜ bin ./kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --describe --topic test1 Topic: test1 PartitionCount: 2 ReplicationFactor: 1 Configs: segment.bytes=1073741824,retention.ms=120000 Topic: test1 Partition: 0 Leader: 3 Replicas: 3 Isr: 3 Topic: test1 Partition: 1 Leader: 1 Replicas: 1 Isr: 1 # 3个broker, 设置3个分片, 2个副本(1主1从), 可以看到分布相当均匀 bash-5.1# ./kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --create --topic test2 --partitions 3 --replication-factor 2 --config retention.ms=120000 Created topic test2. bash-5.1# ./kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --describe --topic test2 Topic: test2 PartitionCount: 3 ReplicationFactor: 2 Configs: segment.bytes=1073741824,retention.ms=120000 Topic: test2 Partition: 0 Leader: 3 Replicas: 3,1 Isr: 3,1 Topic: test2 Partition: 1 Leader: 1 Replicas: 1,2 Isr: 1,2 Topic: test2 Partition: 2 Leader: 2 Replicas: 2,3 Isr: 2,3 # 3个broker, 设置3个分片, 1个副本(1个leader) bash-5.1# ./bin/kafka-topics.sh --create --zookeeper zoo1:2181,zoo2:2181,zoo3:2181 --replication-factor 1 --partitions 3 --topic test3 Created topic test3. bash-5.1# bash-5.1# ./bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --describe --topic test3 Topic: test3 PartitionCount: 3 ReplicationFactor: 1 Configs: segment.bytes=1073741824 Topic: test3 Partition: 0 Leader: 2 Replicas: 2 Isr: 2 Topic: test3 Partition: 1 Leader: 3 Replicas: 3 Isr: 3 Topic: test3 Partition: 2 Leader: 1 Replicas: 1 Isr: 1 # 查看topic列表 ➜ bin ./kafka-topics.sh --list --zookeeper 127.0.0.1:2181 __consumer_offsets test test1 test2 # 删除topic ➜ bin ./kafka-topics.sh --delete --zookeeper 127.0.0.1:2181 --topic test Topic test is marked for deletion. Note: This will have no impact if delete.topic.enable is not set to true. # 查看集群leader不可用分区 ➜ bin ./kafka-topics.sh --zookeeper 127.0.0.1:2181/test --describe --unavailable-partitions # 查看副本不同步的分区详情 ➜ bin ./kafka-topics.sh --zookeeper 127.0.0.1:2181/test --describe --under-replicated-partitions
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 # 查看topic偏移量 ➜ bin ./kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list 127.0.0.1:9092 --topic test test:0:7 # 查看topic指定分区offset的最大值 # -1为最大值 ➜ bin ./kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list 127.0.0.1:9092 --topic test --time -1 test:0:7 # 查看topic指定分区offset的最小值 # -2为最小值 ➜ bin ./kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list 127.0.0.1:9092 --topic test --time -2 test:0:0 # 查看.log数据文件 ➜ bin ./kafka-run-class.sh kafka.tools.DumpLogSegments --files /usr/local/var/lib/kafka-logs/test-0/00000000000000000000.log --print-data-log Dumping /usr/local/var/lib/kafka-logs/test-0/00000000000000000000.log Starting offset: 0 baseOffset: 0 lastOffset: 1 count: 2 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 0 CreateTime: 1607746708893 size: 78 magic: 2 compresscodec: NONE crc: 3385071347 isvalid: true | offset: 0 CreateTime: 1607746708347 keysize: -1 valuesize: 1 sequence: -1 headerKeys: [] payload: 1 | offset: 1 CreateTime: 1607746708893 keysize: -1 valuesize: 1 sequence: -1 headerKeys: [] payload: 2 baseOffset: 2 lastOffset: 4 count: 3 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 78 CreateTime: 1607746710358 size: 87 magic: 2 compresscodec: NONE crc: 2415539616 isvalid: true | offset: 2 CreateTime: 1607746709397 keysize: -1 valuesize: 1 sequence: -1 headerKeys: [] payload: 3 | offset: 3 CreateTime: 1607746709874 keysize: -1 valuesize: 1 sequence: -1 headerKeys: [] payload: 4 | offset: 4 CreateTime: 1607746710358 keysize: -1 valuesize: 1 sequence: -1 headerKeys: [] payload: 5 baseOffset: 5 lastOffset: 6 count: 2 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 165 CreateTime: 1607746712081 size: 78 magic: 2 compresscodec: NONE crc: 449097919 isvalid: true | offset: 5 CreateTime: 1607746711241 keysize: -1 valuesize: 1 sequence: -1 headerKeys: [] payload: 6 | offset: 6 CreateTime: 1607746712081 keysize: -1 valuesize: 1 sequence: -1 headerKeys: [] payload: 7 baseOffset: 7 lastOffset: 7 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 243 CreateTime: 1607750506795 size: 69 magic: 2 compresscodec: NONE crc: 1201654216 isvalid: true | offset: 7 CreateTime: 1607750506795 keysize: -1 valuesize: 1 sequence: -1 headerKeys: [] payload: a baseOffset: 8 lastOffset: 9 count: 2 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 312 CreateTime: 1607750508922 size: 78 magic: 2 compresscodec: NONE crc: 2249065123 isvalid: true | offset: 8 CreateTime: 1607750508188 keysize: -1 valuesize: 1 sequence: -1 headerKeys: [] payload: b | offset: 9 CreateTime: 1607750508922 keysize: -1 valuesize: 1 sequence: -1 headerKeys: [] payload: c baseOffset: 10 lastOffset: 10 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 390 CreateTime: 1607750511875 size: 69 magic: 2 compresscodec: NONE crc: 926719390 isvalid: true | offset: 10 CreateTime: 1607750511875 keysize: -1 valuesize: 1 sequence: -1 headerKeys: [] payload: d # 查看.index索引文件 ➜ bin ./kafka-run-class.sh kafka.tools.DumpLogSegments --files /usr/local/var/lib/kafka-logs/test-0/00000000000000000000.index Dumping /usr/local/var/lib/kafka-logs/test-0/00000000000000000000.index offset: 0 position: 0 Mismatches in :/usr/local/var/lib/kafka-logs/test-0/00000000000000000000.index Index offset: 0, log offset: 1 # 查看.timeindex索引文件 ➜ bin ./kafka-run-class.sh kafka.tools.DumpLogSegments --files /usr/local/var/lib/kafka-logs/test-0/00000000000000000000.timeindex --verify-index-only Dumping /usr/local/var/lib/kafka-logs/test-0/00000000000000000000.timeindex The following indexed offsets are not found in the log. Indexed offset: 0, found log offset: 1
1 2 # 生产消息 ➜ bin ./kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic test
1 2 3 4 5 6 7 8 9 10 # 消费消息 ➜ bin ./kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic test --from-beginning # 指定offset消费消息 # 指定offset=2, 分片0, 最多消费3条 ➜ bin ./kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic test --offset 2 --partition 0 --max-messages 3 3 4 5 Processed a total of 3 messages
消费组管理工具,可以列出所有的消费组,查看消费组详情,删除消费组信息以及重置消费组的offset
--all-groups: 应用到所有的消费组--all-topics:--delete: 删除topic分区的offset,以及拥有者和消费组信息(–group g1 –group g2)--delete-offsets: 删除消费组的offset--describe: 查看消费组信息以及消费者的offset lag--execute: 指定操作,支持reset-offsets操作--export: 导出操作执行到csv,支持reset-offsets--from-file: 指定文件中指定的值重置offset (csv文件)--group: 指定消费组--list: 列出所有的消费组--members: 查看消费组中的成员--state: 查看消费组的状态--offsets: 查看消费组并且列出每个消费组所有topic的分区以及消息的offset lag--reset-offsets: 重置消费组的offset (需要指定如下一个参数)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 # 查看分组列表 ➜ bin ./kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --list console-consumer-10023 console-consumer-20994 # 查看消费组的成员 ➜ bin ./kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --group console-consumer-32644 --members --describe Consumer group 'console-consumer-32644' has no active members. # 查看消费组的offset信息 ➜ bin ./kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --group console-consumer-32644 --offsets --describe Consumer group 'console-consumer-32644' has no active members. # 查看消费组状态 ➜ bin ./kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --group console-consumer-32644 --state --describe Consumer group 'console-consumer-32644' has no active members. GROUP COORDINATOR (ID) ASSIGNMENT-STRATEGY STATE #MEMBERS console-consumer-32644 localhost:9092 (0) Empty 0 # 查看group详情 # CURRENT-OFFSET: 当前消费者群组最近提交的 offset,也就是消费者分区里读取的当前位置 # LOG-END-OFFSET: 当前最高水位偏移量,也就是最近一个读取消息的偏移量,同时也是最近一个提交到集群的偏移量 # LAG:消费者的 CURRENT-OFFSET 与 broker 的 LOG-END-OFFSET 之间的差距 ➜ bin ./kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --group console-consumer-20994 --describe Consumer group 'console-consumer-20994' has no active members. GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID console-consumer-20994 test 0 4 7 3 - - - # 重新设置设置group的offset # 指定group=console-consumer-20994, 重置offset=4 ➜ bin ./kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --group console-consumer-20994 --reset-offsets --topic test --to-offset 4 --execute GROUP TOPIC PARTITION NEW-OFFSET console-consumer-20994 test 0 4 # 把group=console-consumer-20994在topic=test上的offcet恢复到最初 ➜ bin ./kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --group console-consumer-20994 --topic test --reset-offsets --to-earliest –execute WARN: No action will be performed as the --execute option is missing.In a future major release, the default behavior of this command will be to prompt the user before executing the reset rather than doing a dry run. You should add the --dry-run option explicitly if you are scripting this command and want to keep the current default behavior without prompting. GROUP TOPIC PARTITION NEW-OFFSET console-consumer-20994 test 0 0 # 重置Consumer Group的Offset到最新位移 ➜ bin ./kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --group console-consumer-20994 --reset-offsets --topic test --to-latest --execute GROUP TOPIC PARTITION NEW-OFFSET console-consumer-20994 test 0 7 # 把offcet从当前位置往前移动2个,如果是正数就是往后移动。 ➜ bin ./kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --group console-consumer-20994 --topic test --reset-offsets --shift-by -2 --execute GROUP TOPIC PARTITION NEW-OFFSET console-consumer-20994 test 0 5
1 2 3 4 5 # 查看kafka各个broker节点以及topic的磁盘使用率情况 ➜ bin ./kafka-log-dirs.sh --bootstrap-server 127.0.0.1:9092 --describe --topic-list test Querying brokers for log directories information Received log directory information from brokers 0 {"version":1,"brokers":[{"broker":0,"logDirs":[{"logDir":"/usr/local/var/lib/kafka-logs","error":null,"partitions":[{"partition":"test-0","size":243,"offsetLag":0,"isFuture":false}]}]}]}
用来查看和修改kafka相关的配置信息,包含集群的动态配置,topic级别的动态配置等等
--all: 列出给定实体的全部配置文件(默认已经生效的全部参数,如果没有all仅对动态参数生效)--entity-type: 实体类型[topics/clients/users/brokers/broker-loggers]--entity-name: 实体名称[topic名称/client-id/user-name/broker-id]--describe: 列出给定实体的配置文件--force: 强制生效--topic: 指定topic名称--alter: 修改指定实体的配置文件 注意:当使用delete-config和add-config时必须使用--alter--delete-config: 删除指定的配置"k1,k2"--add-config: 给指定的实体增加配置(k=v,k2=[v1,v2,v3],k3=v3)
topic级别的动态参数
cleanup.policy: 清理策略compression.type: 压缩类型(通常建议在produce端控制)delete.retention.ms: 压缩日志的保留时间flush.messages: 持久化message限制flush.ms: 持久化频率follower.replication.throttled.replicas: follower副本限流leader.replication.throttled.replicas: leader副本限流max.message.bytes: 最大的batch的message大小message.downconversion.enable: message向下兼容message.format.version: message格式版本min.insync.replicas: 最小的ISRretention.ms: 日志保留时间retention.bytes: 日志保留大小(通常按照时间限制)segment.bytes: segment的大小限制segment.ms: segment的切割时间unclean.leader.election.enable: 是否允许非同步副本选主(针对可用性设置的一个参数)
broker级别的动态参数
broker级别的动态参数比较多,这里只列举常用的几个
log.retention.ms: 日志保留时间max.connections: 最大连接数max.connections.per.ip: 每个ip的最大连接数message.max.bytes: batch的message的最大限制min.insync.replicas: 最小的ISRnum.io.threads: IO线程数(网络线程数的两倍)num.network.threads: 网络线程数(cpu的2/3较好)num.recovery.threads.per.data.dir: 每个数据目录的恢复线程num.replica.fetchers: 副本的fetchers数量(默认为1,可适当调大)
user级别的参数
SCRAM-SHA-256:SCRAM-SHA-512:consumer_byte_rate: 针对消费者user进行限流producer_byte_rate: 针对生产者进行限流request_percentage: 请求百分比
clients级别参数
consumer_byte_rate: 针对消费者user进行限流producer_byte_rate: 针对生产者进行限流request_percentage: 请求百分比
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 # 修改topic的数据保留时间 ➜ bin ./kafka-configs.sh --bootstrap-server 127.0.0.1:9092 --topic test --add-config retention.ms=10000000 --alter Completed updating config for topic test. # 查看topic的动态参数配置 ➜ bin ./kafka-configs.sh --bootstrap-server 127.0.0.1:9092 --topic test --describe Dynamic configs for topic test are: retention.ms=10000000 sensitive=false synonyms={DYNAMIC_TOPIC_CONFIG:retention.ms=10000000} # 删除topic动态参数配置 ➜ bin ./kafka-configs.sh --bootstrap-server 127.0.0.1:9092 --topic test --alter --delete-config retention.ms Completed updating config for topic test. 查看broker全部的参数(--all会获取全部的参数) ➜ bin ./kafka-configs.sh --bootstrap-server 127.0.0.1:9092 --all --broker-defaults --describe Default configs for brokers in the cluster are:
查看kafka对外的各个api版本.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 # 查看当前kafka版本 ➜ bin ./kafka-broker-api-versions.sh --bootstrap-server 127.0.0.1:9092 --version 2.6.0 (Commit:62abe01bee039651) # 查看集群所有节点的api版本 ➜ bin ./kafka-broker-api-versions.sh --bootstrap-server 127.0.0.1:9092 localhost:9092 (id: 0 rack: null) -> ( Produce(0): 0 to 8 [usable: 8], Fetch(1): 0 to 11 [usable: 11], ListOffsets(2): 0 to 5 [usable: 5], Metadata(3): 0 to 9 [usable: 9], LeaderAndIsr(4): 0 to 4 [usable: 4], StopReplica(5): 0 to 3 [usable: 3], UpdateMetadata(6): 0 to 6 [usable: 6], ControlledShutdown(7): 0 to 3 [usable: 3], OffsetCommit(8): 0 to 8 [usable: 8], OffsetFetch(9): 0 to 7 [usable: 7], FindCoordinator(10): 0 to 3 [usable: 3], JoinGroup(11): 0 to 7 [usable: 7], Heartbeat(12): 0 to 4 [usable: 4], LeaveGroup(13): 0 to 4 [usable: 4], SyncGroup(14): 0 to 5 [usable: 5], DescribeGroups(15): 0 to 5 [usable: 5], ListGroups(16): 0 to 4 [usable: 4], SaslHandshake(17): 0 to 1 [usable: 1], ApiVersions(18): 0 to 3 [usable: 3], CreateTopics(19): 0 to 5 [usable: 5], DeleteTopics(20): 0 to 4 [usable: 4], DeleteRecords(21): 0 to 2 [usable: 2], InitProducerId(22): 0 to 3 [usable: 3], OffsetForLeaderEpoch(23): 0 to 3 [usable: 3], AddPartitionsToTxn(24): 0 to 1 [usable: 1], AddOffsetsToTxn(25): 0 to 1 [usable: 1], EndTxn(26): 0 to 1 [usable: 1], WriteTxnMarkers(27): 0 [usable: 0], TxnOffsetCommit(28): 0 to 3 [usable: 3], DescribeAcls(29): 0 to 2 [usable: 2], CreateAcls(30): 0 to 2 [usable: 2], DeleteAcls(31): 0 to 2 [usable: 2], DescribeConfigs(32): 0 to 3 [usable: 3], AlterConfigs(33): 0 to 1 [usable: 1], AlterReplicaLogDirs(34): 0 to 1 [usable: 1], DescribeLogDirs(35): 0 to 2 [usable: 2], SaslAuthenticate(36): 0 to 2 [usable: 2], CreatePartitions(37): 0 to 2 [usable: 2], CreateDelegationToken(38): 0 to 2 [usable: 2], RenewDelegationToken(39): 0 to 2 [usable: 2], ExpireDelegationToken(40): 0 to 2 [usable: 2], DescribeDelegationToken(41): 0 to 2 [usable: 2], DeleteGroups(42): 0 to 2 [usable: 2], ElectLeaders(43): 0 to 2 [usable: 2], IncrementalAlterConfigs(44): 0 to 1 [usable: 1], AlterPartitionReassignments(45): 0 [usable: 0], ListPartitionReassignments(46): 0 [usable: 0], OffsetDelete(47): 0 [usable: 0], DescribeClientQuotas(48): 0 [usable: 0], AlterClientQuotas(49): 0 [usable: 0]
笔者SpringBoot版本是 2.2.2.RELEASE
pom.xml添加依赖
1 2 3 4 5 <dependency > <groupId > org.springframework.kafka</groupId > <artifactId > spring-kafka</artifactId > <version > 2.4.0.RELEASE</version > </dependency >
生产者配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 @Configuration public class KafkaProducerConfig public Map<String, Object> producerConfigs () Map<String, Object> props = new HashMap<>(); props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.124.5:9093,192.168.124.5:9094,192.168.124.5:9095" ); props.put(ProducerConfig.RETRIES_CONFIG, Integer.MAX_VALUE); props.put(ProducerConfig.ACKS_CONFIG,"all" ); props.put(ProducerConfig.MAX_BLOCK_MS_CONFIG, 6000 ); props.put(ProducerConfig.BATCH_SIZE_CONFIG, 4096 ); props.put(ProducerConfig.LINGER_MS_CONFIG, 1 ); props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 40960 ); props.put(ProducerConfig.MAX_REQUEST_SIZE_CONFIG,1048576 ); props.put(ProducerConfig.CLIENT_ID_CONFIG,"producer.client.id.topinfo" ); props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class); props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class); props.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"none" ); return props; } public ProducerFactory<String, String> producerFactory () return new DefaultKafkaProducerFactory<>(producerConfigs()); } @Bean(name="kafkaTemplate") public KafkaTemplate<String, String> kafkaTemplate () return new KafkaTemplate<>(producerFactory()); } }
消费者配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 @Configuration public class KafkaConsumerConfig private static final String GROUP0_ID = "group0" ; private static final String GROUP1_ID = "group1" ; @Bean KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<Integer, String>> kafkaListenerContainerFactory() { ConcurrentKafkaListenerContainerFactory<Integer, String> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setBatchListener(true ); factory.setConcurrency(4 ); factory.getContainerProperties().setPollTimeout(3000 ); factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL_IMMEDIATE); return factory; } @Bean public ConsumerFactory<Integer, String> consumerFactory () Map<String, Object> map = consumerConfigs(); map.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP0_ID); return new DefaultKafkaConsumerFactory<>(consumerConfigs()); } @Bean public Map<String, Object> consumerConfigs () Map<String, Object> props = new HashMap<>(); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.124.5:9093,192.168.124.5:9094,192.168.124.5:9095" ); props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false ); props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, "100" ); props.put(ConsumerConfig.GROUP_ID_CONFIG, "group-default" ); props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "15000" ); props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest" ); return props; } }
主题配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 @Configuration public class KafkaTopicConfig @Bean public KafkaAdmin kafkaAdmin () Map<String, Object> configs = new HashMap<>(); configs.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.124.5:9093,192.168.124.5:9094,192.168.124.5:9095" ); return new KafkaAdmin(configs); } @Bean public NewTopic topicinfo () return new NewTopic("test" , 3 , (short ) 2 ); } }
消费者服务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 @Slf4j @Service public class KafkaConsumerService @KafkaListener(id = "id7", topics = {Constant.TOPIC}, groupId = "group7") public boolean consumer4 (List<ConsumerRecord<?, ?>> data) for (int i=0 ; i<data.size(); i++) { ConsumerRecord<?, ?> record = data.get(i); Optional<?> kafkaMessage = Optional.ofNullable(record.value()); Long threadId = Thread.currentThread().getId(); if (kafkaMessage.isPresent()) { Object message = kafkaMessage.get(); log.info("consumer:group7 --> message:{}, topic:{}, partition:{}, key:{}, offset:{}, threadId:{}" , message.toString(), record.topic(), record.partition(), record.key(), record.offset(), threadId); } } return true ; } }
手动消费模型
模型一: 每个线程维护1个KafkaConsumer, 可以保证消息partition有序, 增加消费速率需要增加partition, 会触发rebalance
模型二: 拉取线程(1个KafkaConsumer)+工作线程(线程池), 难以维护分区内的消息顺序, 可以在不用增加Partition数量的情况下,只需要增加工作线程数量,便可进一步提升Kafka客户端的并行消费能力
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 public void init () Properties props = new Properties(); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, servers); props.put(ConsumerConfig.GROUP_ID_CONFIG, group); props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest" ); props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true" ); props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000" ); props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, "20" ); props.put(ConsumerConfig.FETCH_MAX_BYTES_CONFIG, String.valueOf(5 * 1024 * 1024 )); consumer = new KafkaConsumer<>(props); executorService = Executors.newSingleThreadExecutor(); executorService.execute(() -> { List<String> topics = new ArrayList<>(); String[] arr = topicNames.split("," ); for (String topic : arr) { topics.add(topic.trim()); } consumer.subscribe(topics); Set<TopicPartition> partitions = consumer.assignment(); while (!stoped) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000 )); for (ConsumerRecord<String, String> record : records) { String json = record.value(); } } }); }
生产者服务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 @Service public class KafkaProducerService @Autowired private KafkaTemplate kafkaTemplate; public void sendMessageSync (String topic, String key, String message) throws InterruptedException, ExecutionException, TimeoutException kafkaTemplate.send(topic, message).get(10 , TimeUnit.SECONDS); } public void sendMessageAsync (String topic, String message) ListenableFuture<SendResult<Integer, String>> future = kafkaTemplate.send(topic, message); ListenableFutureCallback listenableFutureCallback = new ListenableFutureCallback<SendResult<Integer, String>>() { @Override public void onSuccess (SendResult<Integer, String> result) System.out.println("success" ); } @Override public void onFailure (Throwable ex) System.out.println("failure" ); } }; future.addCallback(listenableFutureCallback); } public void test (String topic, Integer partition, String key, String message) throws InterruptedException, ExecutionException, TimeoutException kafkaTemplate.send(topic, partition, key, message).get(10 , TimeUnit.SECONDS); } }
web测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 @RestController public class KafkaProducerController @Autowired private KafkaProducerService producerService; @GetMapping("/sync") public void sendMessageSync (@RequestParam String topic) throws InterruptedException, ExecutionException, TimeoutException producerService.sendMessageSync(topic, null , "同步发送消息测试" ); } @GetMapping("/async") public void sendMessageAsync () producerService.sendMessageAsync("test" ,"异步发送消息测试" ); } @GetMapping("/test") public void test (@RequestParam String topic, @RequestParam(required = false) Integer partition, @RequestParam(required = false) String key, @RequestParam String message) throws InterruptedException, ExecutionException, TimeoutException producerService.test(topic, partition, key, message); } }
考虑增加Topic的分区数,并且同时提升消费组的消费者数量,消费者数=分区数。(两者缺一不可)
调整参数:
fetch.max.bytes
单次获取数据的最大消息数。
max.poll.records <= 吞吐量
单次poll调用返回的最大消息数,如果处理逻辑很轻量,可以适当提高该值。
一次从kafka中poll出来的数据条数,max.poll.records条数据需要在在session.timeout.ms这个时间内处理完
默认值为500
consumer.poll(1000) 重要参数
新版本的Consumer的Poll方法使用了类似于Select I/O机制,因此所有相关事件(包括reblance,消息获取等)都发生在一个事件循环之中。
1000是一个超时时间,一旦拿到足够多的数据(参数设置),consumer.poll(1000)会立即返回 ConsumerRecords<String, String> records。
如果没有拿到足够多的数据,会阻塞1000ms,但不会超过1000ms就会返回。
如果您觉得写的还不错,请关注公众号 【当我遇上你】, 您的支持是我最大的动力。