Java面试必问之Hashmap底层实现原理(JDK1.8)
1. 前言
上一篇从源码方面了解了JDK1.7中Hashmap的实现原理,可以看到其源码相对还是比较简单的。本篇笔者和大家一起学习下JDK1.8下Hashmap的实现。JDK1.8中对Hashmap做了以下改动。
- 默认初始化容量=0
- 引入红黑树,优化数据结构
- 将链表头插法改为尾插法,解决1.7中多线程循环链表的bug
- 优化hash算法
- resize计算索引位置的算法改进
- 先插入后扩容
2. Hashmap中put()过程
笔者的源码是OpenJDK1.8的源码。
JDK1.8中,Hashmap将基本元素由Entry换成了Node,不过查看源码后发现换汤不换药,这里没啥好说的。
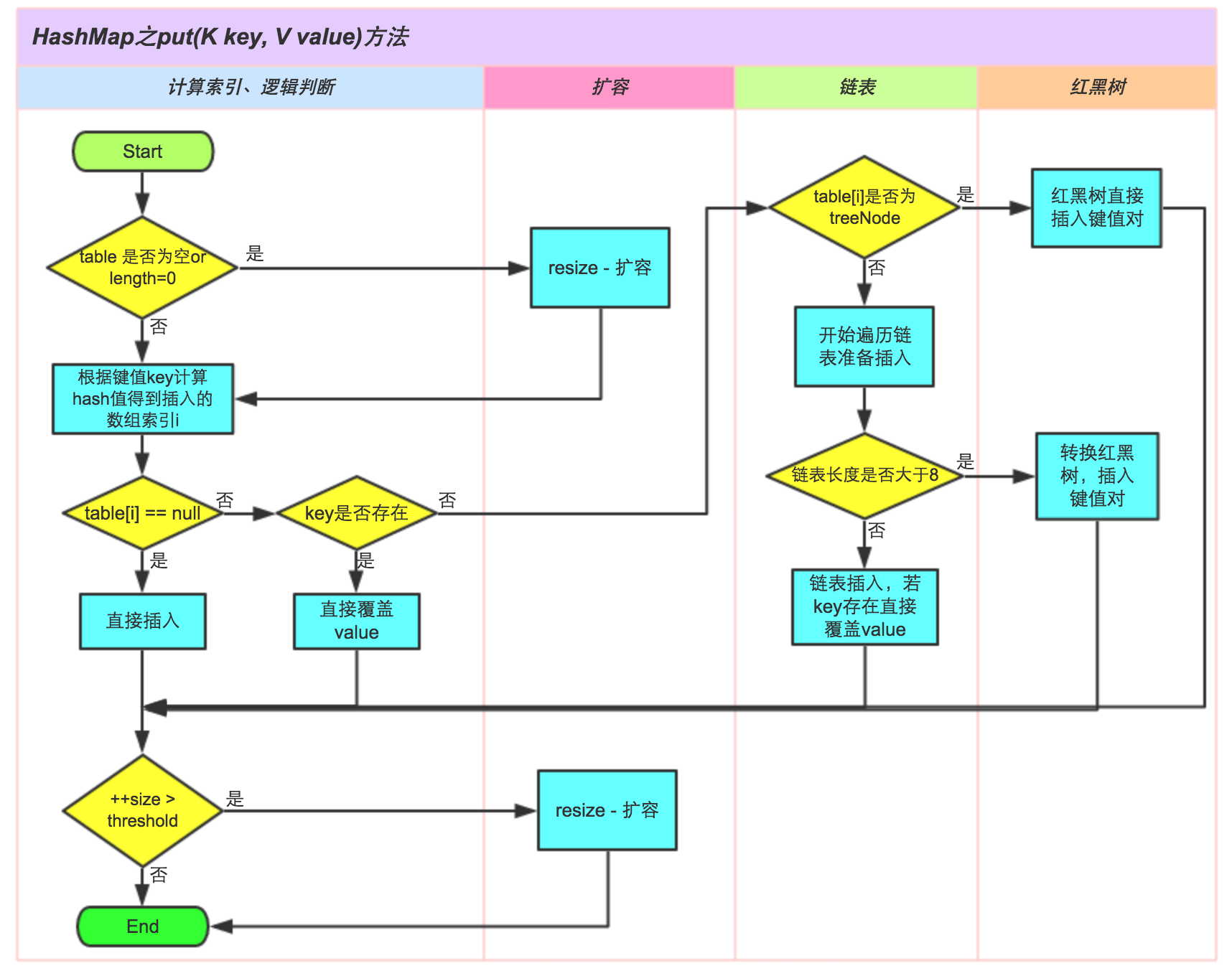
下图是一位大神级别画的图,自己就不再造轮子了。客官请看
put()源码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
| public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
|
基本过程如下:
-
检查数组是否为空,执行resize()扩充;在实例化HashMap时,并不会进行初始化数组)
-
通过hash值计算数组索引,获取该索引位的首节点。
-
如果首节点为null(没发生碰撞),则创建新的数组元素,直接添加节点到该索引位(bucket)。
-
如果首节点不为null(发生碰撞),那么有3种情况
① key和首节点的key相同,覆盖old value(保证key的唯一性);否则执行②或③
② 如果首节点是红黑树节点(TreeNode),将键值对添加到红黑树。
③ 如果首节点是链表,进行遍历寻找元素,有就覆盖无则新建,将键值对添加到链表。添加之后会判断链表长度是否到达TREEIFY_THRESHOLD - 1这个阈值,“尝试”将链表转换成红黑树。
-
最后判断当前元素个数是否大于threshold,扩充数组。
3. Hashmap中get()过程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash &&
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
|
在Hashmap1.8中,无论是存元素还是取元素,都是优先判断bucket上第一个元素是否匹配,而在1.7中则是直接遍历查找。
基本过程如下:
- 根据key计算hash;
- 检查数组是否为空,为空返回null;
- 根据hash计算bucket位置,如果bucket第一个元素是目标元素,直接返回。否则执行4;
- 如果bucket上元素大于1并且是树结构,则执行树查找。否则执行5;
- 如果是链表结构,则遍历寻找目标
4. Hashmap中resize()过程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
| final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1;
}
else if (oldThr > 0)
newCap = oldThr;
else {
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else {
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
|
JDK1.8版本中扩容相对复杂。在1.7版本中,重新根据hash计算索引位置即可;而在1.8版本中分2种情况,下边用图例来解释。


5. 总结
其余还有为什么阈值=8转红黑树,长度<=6 转链表这些问题。基本都是数据科学家根据概率做出的经验值,同时避免数据结构频繁的转换引起的性能开销。
整体看来,JDK1.8主要在数据结构、算法和性能上对1.7进行了优化。
6. AD
欢迎大家关注公众号【当我遇上你】, 每天第一时间与您分享干货。



